








方案详情
文
为了获得特定产区或年份的葡萄酒或葡萄汁的最准确的结果,可以使用一组具有代表性的样本对化学计量模型进行细化。在Lyza 5000 Wine中内置了创建所谓自定义模型的标准操作流程。
方案详情

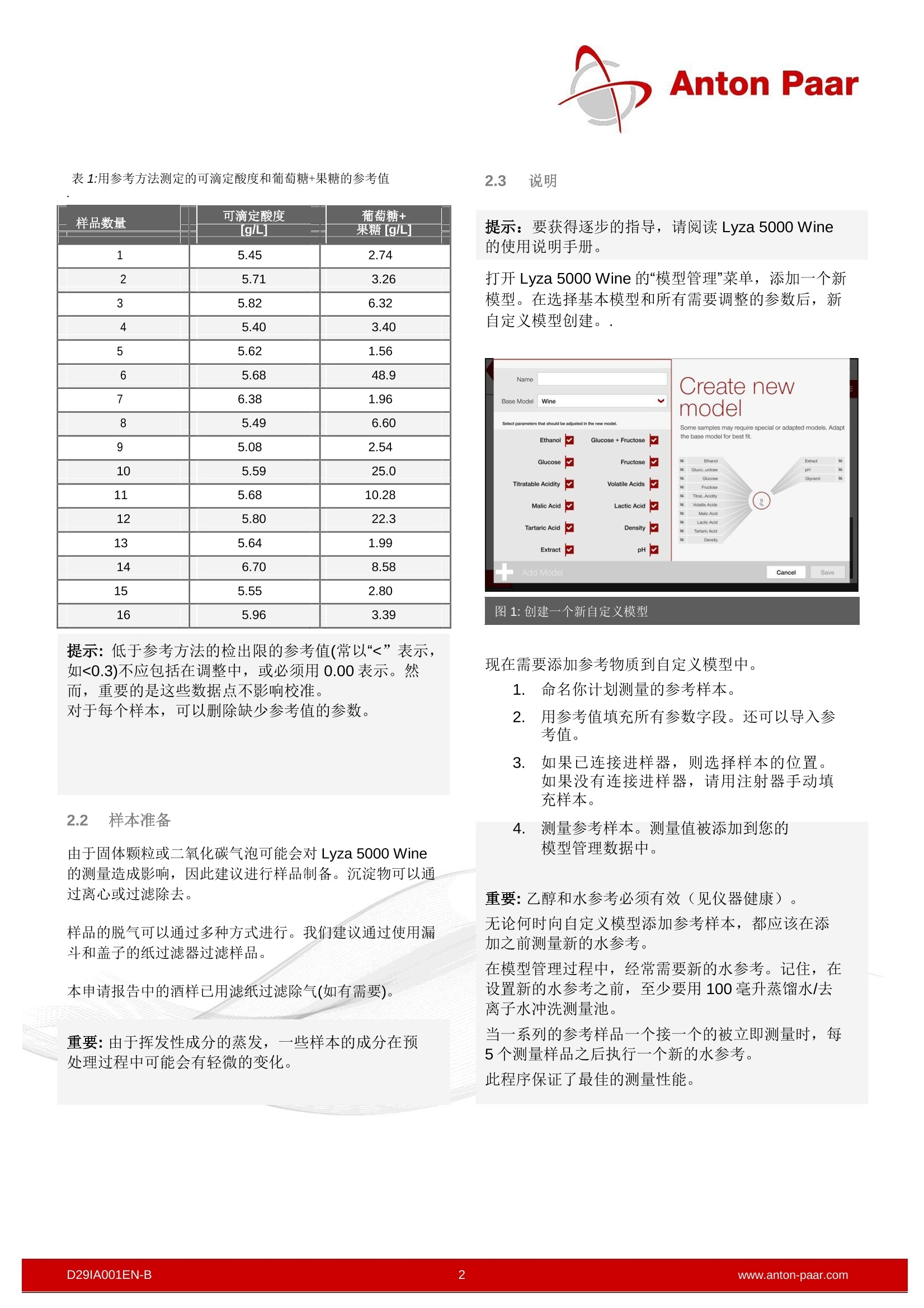
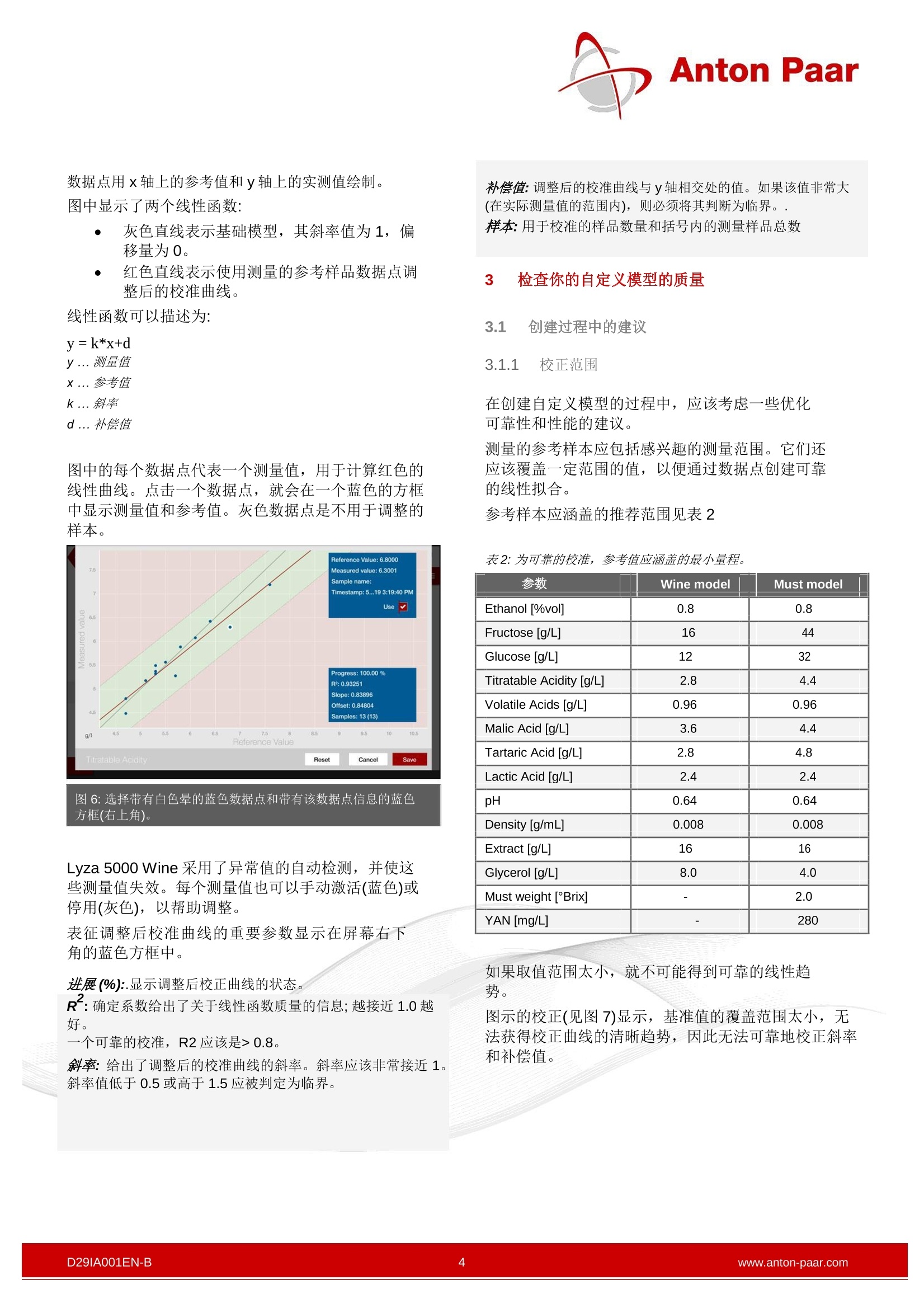
Anton Paar 安东帕模型管理-优化您的分析 相关:独立和连接到 Xsample 520, DMA M 或 Alcolyzer 葡萄酒分析系统使用 Lyza 5000 Wine 为了获得特定产区或年份的葡萄酒或葡萄汁的最准确的结果,可以使用一组具有代表性的样本对化学计量模型进行细化。在 Lyza 5000 Wine 中内置了创建所谓自定义模型的标准操作流程。 1为什么创建一个自定义模型I? 葡萄汁和成品酒都是天然产品。它们的味道和成分取决于所使用的葡萄。不仅是葡萄的种类,还有葡萄生长的地点,生长过程中的气候和天气条件以及许多其他因素都会影响葡萄酒的化学成分。 化学计量模型是基于各种各样的葡萄酒,因此涵盖了世界各地的样品类型。 通常在一个实验室测量的样品位于一个参数的特征范围内(例如低糖,0到5g/L果糖),因此,仅代表基本模型所涵盖范围的一小部分,该模型内置在 Lyza 5000Wine中(例如,果糖0到160 g/L). 为了优化化学计量模型并使其适合于感兴趣的样本,可以创建自定义模型。 在这个应用报告中,基于“wine”基本模型为葡萄酒生产者创建了一个自定义模型。 1.1 什么是自定义模型? 自定义模型可以理解为对给定基本模型的调整。Lyza5000 Wine 中集成了两个不同的基本模型,即基本模型“Wine”和“Must” Lyza 5000 Wine的基本模型是用来自世界各地的葡萄酒校准的,因此涵盖了大量的样品。 在创建特定于某一样本的自定义模型时,需要选择执行调整的基本模型。这意味着自定义模型并不是一个全新的化学计量模型,而是将校准优化到用于调整的特定样本集。 用户不需要任何化学计量模型或统计方法的知识。 2 如何创建一个自定义模型 2.1 所需材料 要创建自定义模型,建议测量大约15个感兴趣的代表性样本。添加更多的样本将进一步增加自定义模型的可靠性。 需要使用自定义模型优化所有参数的渗考值。这些参数的浓度必须通过参考方法(如滴定法、蒸馏法、酶法等)确定。 完成自定义模型所需的样本数量还取决于参考数据的质量和这些参考样本所涵盖的值的范围。可以添加到自定义模型的参考样本的数量没有限制。添加更多的参数可以提高自定义模型的健壮性。 调整程序可以完全在Lyza 5000 Wine 上完成,无需外部PC。 在这份应用报告中,我们使用了具有“可滴定的酸度”和“葡萄糖+果糖"参数参考值的葡萄酒样品,以一种典型的方式进行了校准(见表1)。 表1:用参考方法测定的可滴定酸度和葡萄糖+果糖的参考值 样品数量 可滴定酸度 葡萄糖+ [g/L] 果糖[g/L] 1 5.45 2.74 2 5.71 3.26 3 5.82 6.32 4 5.40 3.40 5 5.62 1.56 6 5.68 48.9 7 6.38 1.96 8 5.49 6.60 9 5.08 2.54 10 5.59 25.0 11 5.68 10.28 12 5.80 22.3 13 5.64 1.99 14 6.70 8.58 15 5.55 2.80 16 5.96 3.39 提示:低于参考方法的检出限的参考值(常以“<”表示,如<0.3)不应包括在调整中,或必须用0.00表示。然而,重要的是这些数据点不影响校准。 对于每个样本,可以删除缺少参考值的参数。 2.2 样本准备 样品的脱气可以通过多种方式进行。我们建议通过使用漏斗和盖子的纸过滤器过滤样品。 本申请报告中的酒样已用滤纸过滤除气(如有需要)。 重要:由于挥发性成分的蒸发,一些样本的成分在预处理过程中可能会有轻微的变化。 2.3 说明 提示:要获得逐步的指导,请阅读 Lyza 5000 Wine的使用说明手册。 打开 Lyza 5000 Wine 的“模型管理”菜单,添加一个新模型。在选择基本模型和所有需要调整的参数后,新自定义模型创建。. 图1:创建一个新自定义模型 现在需要添加参考物质到自定义模型中。 1.命名你计划测量的参考样本。 2. 用参考值填充所有参数字段。还可以导入参考值。 3. 如果已连接进样器,则选择样本的位置。如果没有连接进样器,请用注射器手动填充样本。 4.测量参考样本。测量值被添加到您的模型管理数据中。 由于固体颗粒或二氧化碳气泡可能会对 Lyza 5000 Wine的测量造成影响,因此建议进行样品制备。沉淀物可以通过离心或过滤除去。 重要:乙醇和水参考必须有效(见仪器健康)。 无论何时向自定义模型添加参考样本,都应该在添加之前测量新的水参考。 在模型管理过程中,经常需要新的水参考。记住,在设置新的水参考之前,至少要用100毫升蒸馏水/去离子水冲洗测量池。 当一系列的参考样品一个接一个的被立即测量时,每5个测量样品之后执行一个新的水参考。 此程序保证了最佳的测量性能。 图2:用户可以在界面左侧添加参考数据,自定义模型进度条的右侧会显示。 进度条会随着每一个新添加的参考样本而改变。 每个单独参数的进程可以在进度条中观察到,该进度条随着校准质量的增加而增长。 绿色进度条表示该参数的最低要求已经达到。增加更多的参考样本仍然是可能的,并将进一步提高校准的稳健性。 对于每个校准曲线的质量,也要注意第2.4章和第3章中列出的要点。 进度条的状态取决于测量样本的数量和测量结果与参考值之间的相关性的质量。当所有进度条的状态变绿,模型准备好校正,那么您就已经达到了所需的最低参考样本量. 点击“校正”,执行基本模型的校正,保存校正的自定义模型。 图4:模型准备好校正. 提示:参考样本仍然可以添加到调整后的自定义模型中。点击“添加参考”输入样品名称和参考值添加另一个参考样本。 提示:也可以使用未经调整的模型(进行中)进行测量。在开始测量时,所有可用模型的列表可供选择。 2.4 校正曲线 点击可以显示和调整每个参数的校准曲线。 校准曲线是由执行的参考测量定义的直线。 校准曲线是由执行的参考测量(蓝色和灰色数据点)定义的直线。 图5:良好校正曲线举例 数据点用x轴上的参考值和y轴上的实测值值制。 图中显示了两个线性函数: ● 灰色直线表示基础模型,其斜率值为1,偏移量为0. 红色直线表示使用测量的参考样品数据点调整后的校准曲线。 线性函数可以描述为: y=k*x+d y...测量值 x...参考值 k...斜率 d...补偿值 图中的每个数据点代表一个测量值,用于计算红色的线性曲线。点击一个数据点,就会在一个蓝色的方框中显示测量值和参考值。灰色数据点是不用于调整的样本。 图6:选择带有白色晕的蓝色数据点和带有该数据点信息的蓝色方框(右上角)。 Lyza 5000 Wine 采用了异常值的自动检测,并使这些测量值失效。每个测量值也可以手动激活(蓝色)或停用(灰色),以帮助调整。 表征调整后校准曲线的重要参数显示在屏幕右下角的蓝色方框中。 进展(%):.显示调整后校正曲线的状态。 :确定系数给出了关于线性函数质量的信息;越接近1.0越好。 一个可靠的校准,R2应该是>0.8。 斜率:给出了调整后的校准曲线的斜率。斜率应该非常接近1。斜率值低于0.5或高于1.5应被判定为临界。 补偿值:调整后的校准曲线与y轴相交处的值。如果该值非常大(在实际测量值的范围内),则必须将其判断为临界。. 样本:用于校准的样品数量和括号内的测量样品总数 3 检查你的自定义模型的质量 3.1 创建过程中的建议 3.1.1 校正范围 在创建自定义模型的过程中,应该考虑一些优化可靠性和性能的建议。 测量的参考样本应包括感兴趣的测量范围。它们还应该覆盖一定范围的值,以便通过数据点创建可靠的线性拟合。 参考样本应涵盖的推荐范围见表2 表2:为可靠的校准,参考值应涵盖的最小量程。 参数 Wine model Must model Ethanol [%vol] 0.8 0.8 Fructose [g/L] 16 44 Glucose [g/L] 12 32 Titratable Acidity [g/L] 2.8 4.4 Volatile Acids [g/L] 0.96 0.96 Malic Acid [g/L] 3.6 4.4 Tartaric Acid [g/L] 2.8 4.8 Lactic Acid [g/L] 2.4 2.4 pH 0.64 0.64 Density [g/mL] 0.008 0.008 Extract [g/L] 16 16 Glycerol [g/L] 8.0 4.0 Must weight [Brix] - 2.0 YAN[mg/L] 280 如果取值范围太小,就不可能得到可靠的线性趋势。 图示的校正(见图7)显示,基准值的覆盖范围太小,无法获得校正曲线的清晰趋势,因此无法可靠地校正斜率和补偿值。 通过包括/不包括单个数据点来改变斜率和偏移量也是定制校准质量的一个指标。如果有较强的变化,则校准曲线的权重不均匀. 图7:参考值范围太小,无法进行可靠的校准。无法使用自定义校准(红线)。 3.1.2 相关性缺失 如果测量值和参考值没有产生明显的相关性,那么使用这种自定义校准是不合理的(见图8)。 图9:校准以一个数据点为主,自定义校正无法使用。 缺失的相关性可能由不同因素导致: 3.1.4 良好的校正曲线 ● 参考方法和基本模型中使用的参考方法不同。 由于 Lyza 5000 Wine.错误/遗失水参考,测量值有误。 ● 参考值被错误的分配给测量。p. 合理的校准曲线(见图10)的特征是线性拟合趋势明显,其结果是参考值范围广泛。异常值将自动取消选择,至少15个参考样本必须包含在自定义校准中。 图10:良好校正曲线举例 图8:测量值和参考值间没有相关性,自定义校正无法使用。 3.2 测量实验样品 3.1.3 数据点的不平衡分布 可能发生的情况是,校准曲线主要由单个数据点控制(参见图9)。 在创建自定义模型之后,应该确保模型交付可靠的结果。检查模型质量的最佳方法是测量一组测试样本,并将来自自定义模型的结果与来自参考方法的结果进行比较 始终确保参考值均匀地分布在整个感兴趣的范围内,并避免造成校准曲线偏差的数据云。 如果自定义模型创建合理,那么测试样本的测量结果比使用基本模型更接近参考值。 理想测试样品的条件: 1. 样本不能是用于创建自定义模型的样本集的一部分。 2. 样品应与模型使用的样品具有相似的特征[相同的年份,相同的区域,相同的测量结果范围]。 3. 测试样品的参考值已知。 从该葡萄酒生产商的三个葡萄酒样品用于检查自定义模型的质量。每个葡萄酒用基本模型测量三次,用自定义模型测量三次。计算并比较平均值。 Lyza 5000 Wine 的结果与参考值的偏差显示在表3和表4. 表3:葡萄糖+果糖[g/L]:用基本模型和自定义模型测量的结果和参考值的计算偏差 偏差 偏差 样品号 基本模型 自定义模型 17 -1.6 0.0 18 -1.5 0.5 19 -0.7 0.2 表4: Titratable acidity [g/L]: 用基本模型和自定义模型测量的结果和参考值的计算偏差 样品号 偏差 偏差 基本模型 自定义模型 17 -0.56 -0.24 18 -0.59 -0.17 19 0.2 -0.14 从自定义模型预测的值与参考值的偏差小于从基本模型预测的值。该模型已成功地针对该葡萄酒生产商的葡萄酒进行了调整。自定义模型显示的值更接近于参考值。 4 总结 Lyza 5000 Wine 的模型管理是一个为特定的一组样本创建专门模型的简单的工具[例如干葡萄酒,高糖含量,高酒精含量等]。通过使用一组具有代表性的示样本,任何人都可以创建自定义模型。 ( 安东帕创建于1922年,总部位于奥地利。安东帕在密度和浓度的测量,溶解二氧化碳的测 定, 以 及在流变学和粘度测量领域处于世界领先地位。致力于为全球工业和科研客户提供最合适的仪器,产品范围涵盖密度计、微波消解仪、微波合成仪、旋光仪、折光仪、黏度计、流变仪、馏程分析仪、闪点测试仪、x-射线结构分析、固体表面电位分析仪、表面力学性能测试仪器、在线分析检测仪表、颗粒特性分析、原子力显微镜以及固体材料直接表征等。 ) DAN-Bwww.anton-paar.com 为了获得特定产区或年份的葡萄酒或葡萄汁的最准确的结果,可以使用一组具有代表性的样本对化学计量模型进行细化。在Lyza 5000 Wine中内置了创建所谓自定义模型的标准操作流程。
确定




还剩4页未读,是否继续阅读?

产品配置单

安东帕(上海)商贸有限公司为您提供《葡萄酒中产品品质检测方案(红外光谱仪)》,该方案主要用于葡萄酒及果酒中营养成分检测,参考标准--,《葡萄酒中产品品质检测方案(红外光谱仪)》用到的仪器有安东帕葡萄酒分析仪FTIR Lyza 5000 Wine
相关方案
更多
该厂商其他方案
更多